手書き数字を認識するエキスパートアドバイザー
今回紹介するのは、手書き数字を認識するためのエキスパートアドバイザー(EA)です。このEAは、MNISTデータベースを基にしています。このデータベースには、トレーニング用の60,000枚とテスト用の10,000枚の画像が含まれています。これらの画像は、元々のNISTセットから作成されたもので、米国国勢調査局から取得した20x20ピクセルの白黒サンプルを再構成したものです。
手書き数字認識用のモデル「mnist.onnx」は、GithubのModel Zooからダウンロードできます(opset 8)。興味がある方は、最新のONNXランタイムでサポートされていないopset 1のモデルを除いて、他のモデルも試してみてください。驚くべきことに、出力ベクトルは一般的な分類モデルで使われるSoftmax活性化関数を通していませんでしたが、私たちが独自に実装することは簡単です。
int PredictNumber(void)
{
staticmatrixf image(28,28);
staticvectorf result(10);
PrepareMatrix(image);
if(!OnnxRun(ExtModel,ONNX_DEFAULT,image,result))
{
Print("OnnxRun error ",GetLastError());
return(-1);
}
result.Activation(result,AF_SOFTMAX);
int predict=int(result.ArgMax());
if(result[predict]<0.8)
Print(result);
Print("value ",predict," predicted with probability ",result[predict]);
return(predict);
}
マウスを使って特別なグリッドに数字を描くことができます。左ボタンを押し続けて描いた後、CLASSIFYボタンを押すことで、描いた数字を認識させることができます。
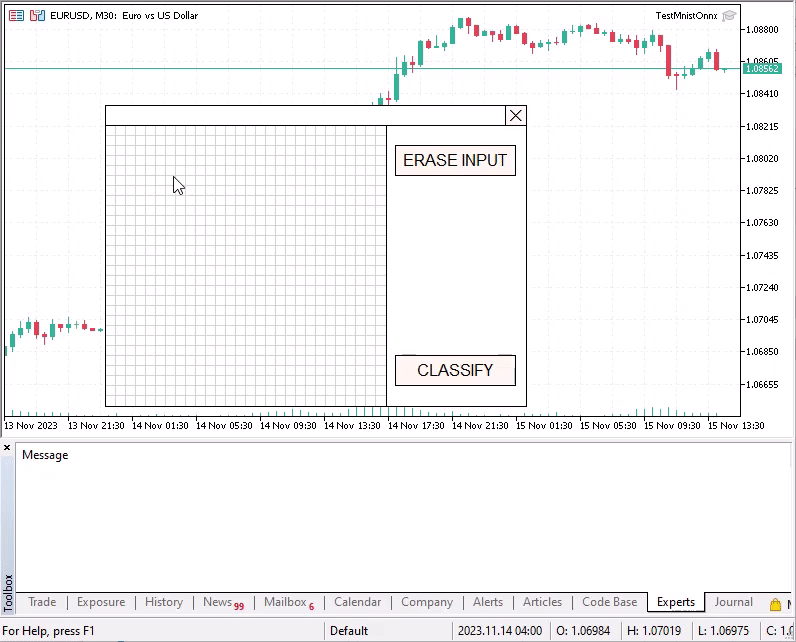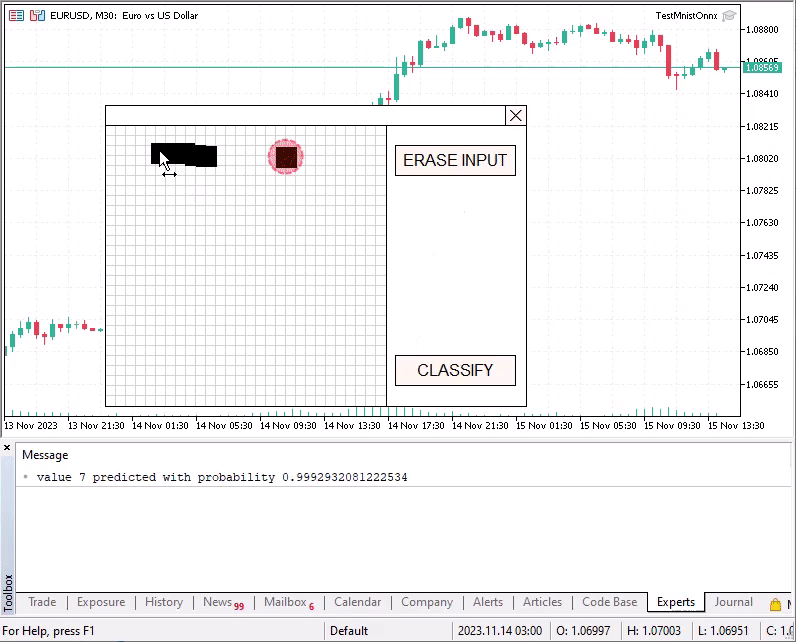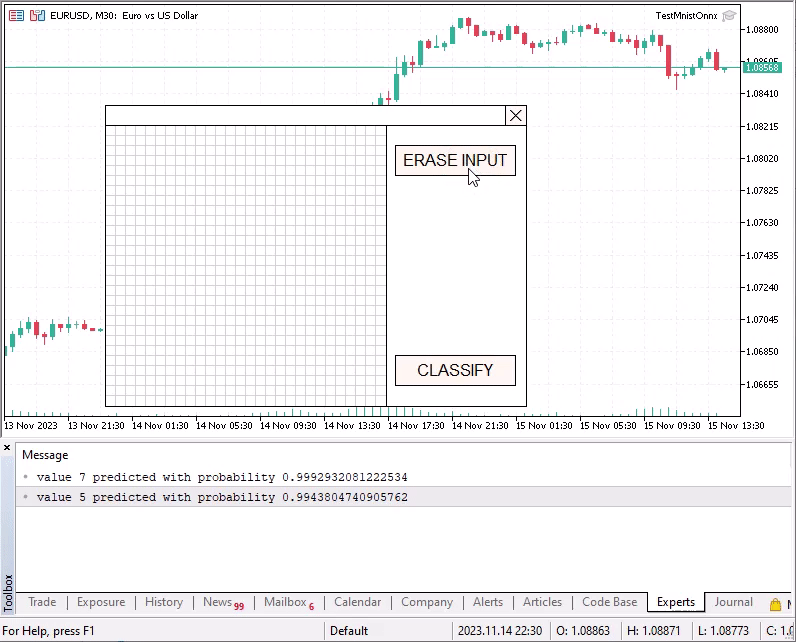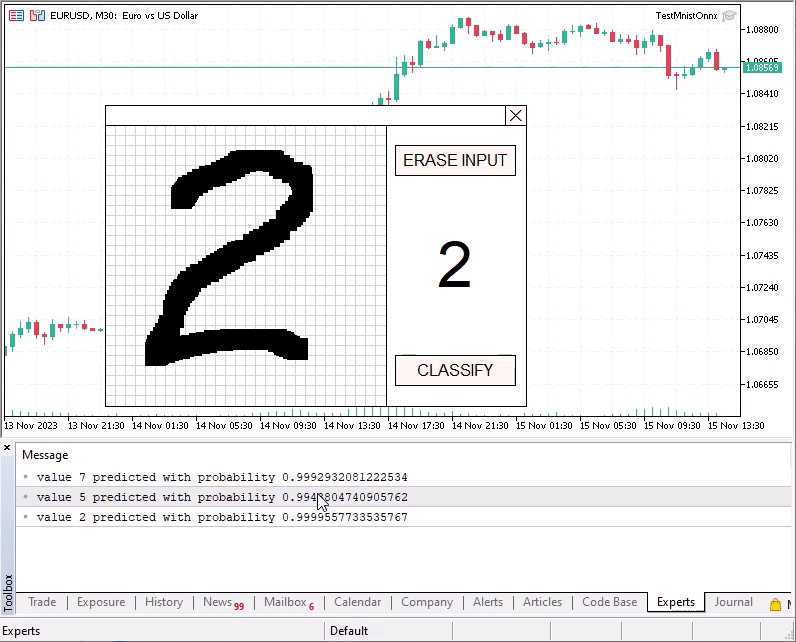
認識された数字の確率が0.8未満の場合、各クラスの確率を含むベクトルがログに表示されます。例えば、空の未記入の入力フィールドを分類してみると良いでしょう。
[0.095331445,0.10048489,0.10673151,0.10274081,0.087865397,0.11471312,0.094342403,0.094900772,0.10847695,0.09441267]
value 5 predicted with probability 0.11471312493085861
不思議なことに、数字の9(9)の認識精度は特に低いことが分かりました。左に傾いた数字はより正確に認識される傾向があります。




コメント 0