こんにちは、トレーダーの皆さん!今日は、k近傍法を基にしたトレード分類器についてお話しします。この手法は、メモリを持つ機械の実装に基づいており、正直なところ、期待した結果には至りませんでした。おそらく、私が触れる時間が足りなかったからでしょう。また、知識が不足していた部分もあるかもしれません。とにかく、皆さんとこのアプローチについて議論できればと思い、ここに投稿しました。もしかしたら、みんなで考えることで新しいアイデアが生まれるかもしれません。
この取引分類器は、Euclidean_Metric関数を使っており、トレードや市場状況を説明するためのベクターデータを使用します。この関数は、入力ベクトルがベースにあるグループのいずれかに属するかどうかを判断します。ユーザーが定義したグループに基づいて、トレードが利益を出した場合はクラス1、損失を出した場合はクラス0に分類されます。多次元ベクトルの最近傍を探す際には、ユークリッド距離を使用します。その後、クラス1に属するk個のベクトルが何個あるかを数え、その値を隣接ベクトルの総数で割ることで、入力ベクトルがクラス1に属する確率を算出します。
ただし、選択したベクトルの座標が「悪い」場合、分類結果はあまり信頼できません(単純に0.5以上または以下ではありません)。そのため、追加の閾値を設け、将来のトレードが利益をもたらす確率が0.7を超える場合にのみ市場に入るようにしています。移動平均の比率をベクトルの座標とし、ベクトル(トレード)が一度分類されれば、その分類をフォワードテストにも使用できると考えています。しかし、実際はそう簡単ではありません。なぜk近傍法を選んだかというと、最も近い隣人が異常値である場合、この異常値が分類に影響を与える可能性があるからです。もっと詳しい説明については、S. Haykinの「Neural Networks: A Comprehensive Foundation」を参考にしてください。
この分類器には2つの問題があります:
- 市場状況や将来のトレードを正確に記述する静的データを見つけること。
- 数学的な演算が多いため、計算に時間がかかること(ちなみに、PNNよりは少し少ないです)。
要するに、問題は従来のシステムトレーディングとほぼ同じです。しかし、この分類器の利点は、トレーダーが直感的に把握できない条件を形式化できることです。つまり、特定の指標の値がトレードを開くかどうかに影響を与えていることを見抜けるのです。
さて、実装について具体的にお話ししましょう。
- Base - trueの場合、ベクターデータのファイルが書き込まれます。falseの場合は、分類されたトレードが行われます。
- buy_threshold=0.6 - すべての買いポジションの閾値です。
- sell_threshold=0.6 - 売りポジションの閾値です。
- inverse_position_open?=true - 利益が出る可能性が非常に低い場合、なぜ逆ポジションで市場に入らないのか?このフラグがそのようなポジションを有効にします。
- invers_buy_threshold=0.3 - 利益が出る可能性が小さい場合に、売りトレードを開くための閾値です。
- invers_sell_threshold=0.3 - 同様です。
- fast=12 - MACDのパラメータです。
- slow=34 - 同様です。
- tp=40 - テイクプロフィット。
- sl=30 - ストップロス。
- close_orders=false - 反対の信号で利益が出ている場合のみ、注文を閉じるフラグです。
使用法:まず、フラグBaseをtrueに設定し、slをtpに設定して履歴で実行します(1回だけ!)、その際にベクターファイルが書き込まれます。次回はフラグをfalseに設定し、閾値を最適化することをお勧めします。私は最初のレポート(分類なし)に基づいて閾値を選びます。成功の確率が0.5の場合、閾値は0.6と0.4(ポジションを反転させるため)になります。
もう一度言いますが、これは一例です。この分類器は、他のシステムトレーディングにも同様に適用できます。
分類前:
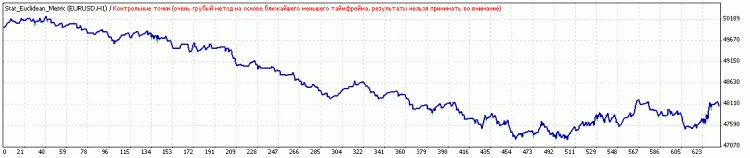
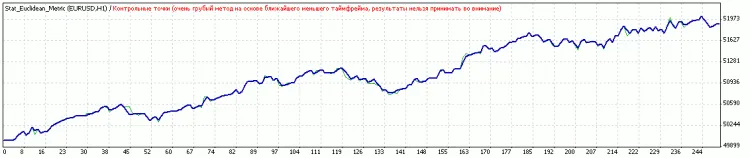
後、閾値の最適化後。
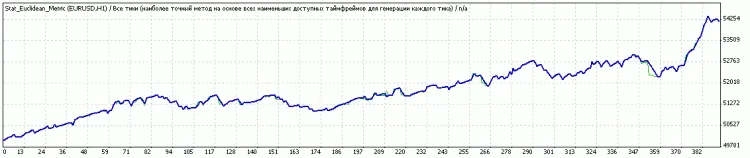
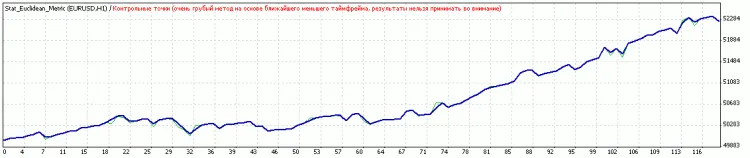




コメント 0