Bienvenue dans cet article où nous allons explorer l'implémentation d'un système de classification basé sur les k-nearest neighbors. J'ai récemment travaillé sur cette approche, mais je dois avouer qu'elle n'a pas donné les résultats escomptés. Cela pourrait être dû à un manque de temps consacré aux ajustements ou simplement à des lacunes dans mes connaissances. Quoi qu'il en soit, j'ai décidé de partager mes réflexions pour en discuter avec vous, en espérant que cela pourrait donner lieu à des idées intéressantes.
La fonction Euclidean_Metric agit comme un classificateur. En utilisant une base de vecteurs qui décrit soit les opérations de trading, soit les situations de marché, cette fonction détermine si un vecteur d'entrée appartient à l'une des catégories définies. Dans notre exemple, c'est simple : un trade qui se termine par un résultat positif fait partie de la classe 1, tandis qu'un résultat négatif appartient à la classe 0. La recherche des voisins les plus proches d'un vecteur multidimensionnel se fait via la distance euclidienne. Ensuite, on compte combien de ces k vecteurs appartiennent à la classe 1. Ce chiffre est divisé par le nombre total de voisins (c'est-à-dire k) pour obtenir la probabilité que le vecteur appartienne à la classe 1. Cependant, en raison de la sélection parfois aléatoire des coordonnées des vecteurs, cette classification ne peut pas toujours être entièrement fiable, surtout si le résultat est juste au-dessus ou en dessous de 0,5. C'est pourquoi j'ai ajouté une valeur seuil : si la probabilité qu'un trade soit rentable dépasse 0,7 par exemple, alors j'ouvre une position sur le marché. Les ratios des moyennes mobiles servent de mesures (coordonnées) pour les vecteurs, en supposant qu'ils restent statiques. Une fois les vecteurs classés, cette classification pourrait également être utilisée lors des tests futurs. Mais ce n'est pas si simple :) Pourquoi opter pour les k-nearest neighbors ? Tout simplement parce qu'en considérant seulement le premier voisin le plus proche, on risque de tomber sur une valeur aberrante sans prendre en compte un cluster de vecteurs opposés à proximité. Pour un aperçu détaillé, je recommande le livre de S. Haykin : « Neural Networks: A Comprehensive Foundation ».
Le classificateur présente deux problèmes principaux :
- 1) Trouver des données statiques qui décrivent les situations de marché (ou les trades futurs) avec la précision requise pour une classification correcte.
- 2) Le volume important des opérations mathématiques, ce qui entraîne des temps de calcul relativement longs… (juste un peu moins que le PNN).
En résumé, ces problèmes sont assez similaires à ceux rencontrés avec les systèmes de trading conventionnels. L'avantage ici est que le classificateur peut formaliser des conditions que le trader ne peut pas percevoir mais qu'il ressent intuitivement, ce qui influence ses décisions de trading.
Maintenant, parlons de l'implémentation concrète.
Base - true pour écrire un fichier avec la base de vecteurs, false pour trader avec classification.
buy_threshold=0.6 : seuil pour toutes les positions d'achat.
sell_threshold=0.6 : de même pour les ventes.
inverse_position_open=?true; C'est un point intéressant. Si la probabilité d'un trade rentable est très faible, pourquoi ne pas entrer sur le marché avec une position inversée ? Ce flag permet de telles positions.
invers_buy_threshold=0.3 : seuil, lorsque la probabilité d'une position d'achat rentable est inférieure, alors ouvrez une vente.
invers_sell_threshold=0.3 : de même pour les ventes.
fast=12 : paramètres de MACD.
slow=34;
tp=40 : Take profit.
sl=30 : Stop loss.
close_orders=false; flag qui permet de fermer uniquement sur un signal opposé si l'ordre est en profit.
Utilisation : D'abord, activez le flag Base sur true, ajustez sl à tp et exécutez l'historique (une seule fois !), le fichier de vecteur sera enregistré. La prochaine fois, mettez Base sur false et il est recommandé d'optimiser les seuils. Je choisis ces derniers selon le premier rapport (sans classification). Si la probabilité de succès est de 0,5, alors les seuils sont de 0,6 et 0,4 (pour inverser la position).
Encore une fois, c'est un exemple, le classificateur peut s'appliquer à d'autres systèmes de trading de la même manière, avec d'autres données d'entrée.
Avant classification :
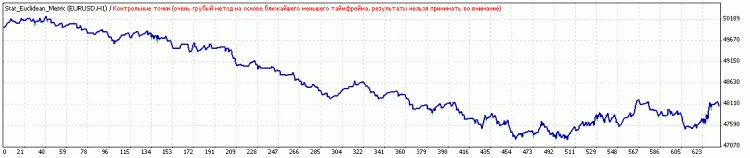
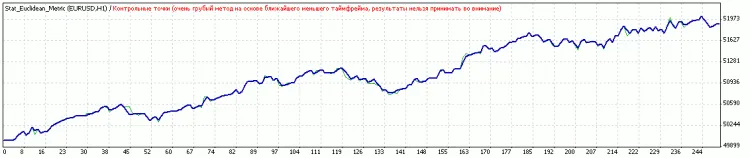
Après, avec optimisation des seuils.
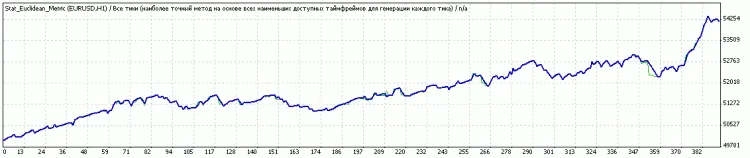
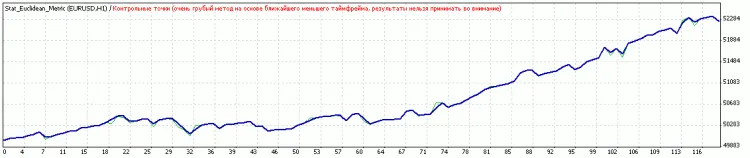




Commentaire 0