लेखक: gpwr
संस्करण इतिहास:
- 06/26/2009 - नया संकेतक BPNN Predictor with Smoothing.mq4 जोड़ा गया, जिसमें कीमतों को भविष्यवाणियों से पहले EMA का उपयोग करके स्मूथ किया गया है।
- 08/20/2009 - गणना कोड में सुधार किया गया ताकि गणितीय अपवाद को रोका जा सके; BPNN.cpp और BPNN.dll को अपडेट किया गया।
- 08/21/2009 - DLL निष्पादन के अंत में मेमोरी का साफ़ करना जोड़ा गया; BPNN.cpp और BPNN.dll को अपडेट किया गया।
न्यूरल नेटवर्क का संक्षिप्त सिद्धांत:
न्यूरल नेटवर्क एक समायोज्य मॉडल है जो इनपुट के कार्यों के रूप में आउटपुट का निर्माण करता है। यह कई परतों में बंटा होता है:
- इनपुट परत, जिसमें इनपुट डेटा होता है
- हिडन परत, जिसमें प्रोसेसिंग नोड्स होते हैं जिन्हें न्यूरॉन्स कहा जाता है
- आउटपुट परत, जिसमें एक या एक से अधिक न्यूरॉन्स होते हैं, जिनका आउटपुट नेटवर्क का आउटपुट होता है।
सभी निकटवर्ती परतों के नोड्स आपस में जुड़े होते हैं। इन कनेक्शनों को सिनैप्स कहा जाता है। प्रत्येक सिनैप्स का एक निर्धारित स्केलिंग गुणांक होता है, जिसके द्वारा डेटा को सिनैप्स के माध्यम से गुणा किया जाता है। इन स्केलिंग गुणांकों को वेट्स (w[i][j][k]) कहा जाता है। एक फीड-फॉरवर्ड न्यूरल नेटवर्क (FFNN) में डेटा को इनपुट से आउटपुट की ओर भेजा जाता है। यहाँ एक FFNN का उदाहरण है जिसमें एक इनपुट परत, एक आउटपुट परत और दो हिडन लेयर हैं:
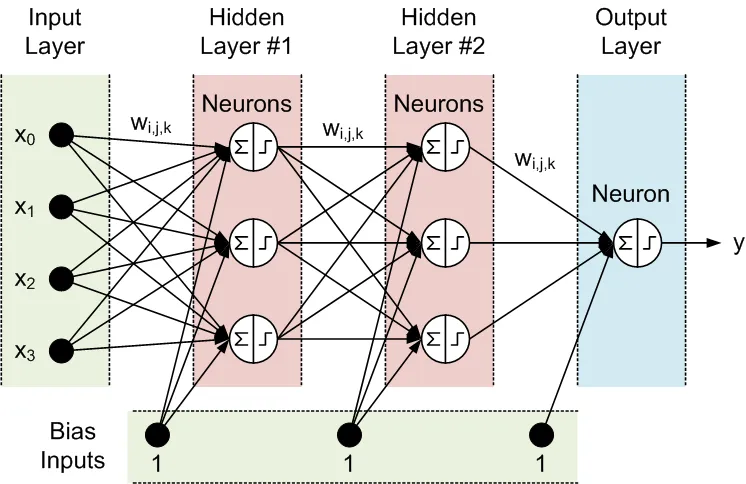
एक FFNN की टोपोलॉजी को अक्सर इस प्रकार संक्षिप्त किया जाता है: <इनपुट्स की संख्या> - <पहली हिडन परत में न्यूरॉन्स की संख्या> - <दूसरी हिडन परत में न्यूरॉन्स की संख्या> -...- <आउटपुट्स की संख्या>। उपरोक्त नेटवर्क को 4-3-3-1 नेटवर्क कहा जा सकता है।
डेटा को न्यूरॉन्स द्वारा दो चरणों में संसाधित किया जाता है, जो क्रमशः सर्कल के भीतर एक योग चिन्ह और एक चरण चिन्ह द्वारा दर्शाए जाते हैं:
- सभी इनपुट्स को संबंधित वेट्स के साथ गुणा किया जाता है और योग किया जाता है।
- परिणामी योग न्यूरॉन के एक्टिवेशन फंक्शन द्वारा संसाधित किए जाते हैं, जिसका आउटपुट न्यूरॉन का आउटपुट होता है।
यही न्यूरॉन का एक्टिवेशन फंक्शन न्यूरल नेटवर्क मॉडल को नॉन-लिनियरिटी प्रदान करता है। इसके बिना, हिडन परतों की कोई आवश्यकता नहीं होती और न्यूरल नेटवर्क एक लीनियर ऑटोरिग्रेसिव (AR) मॉडल बन जाता है।
NN कार्यों के लिए संलग्न लाइब्रेरी फ़ाइलें तीन एक्टिवेशन फंक्शंस के बीच चयन करने की अनुमति देती हैं:
- सिग्मोइड sigm(x)=1/(1+exp(-x)) (#0)
- हाइपरबोलिक टेंजन्ट tanh(x)=(1-exp(-2x))/(1+exp(-2x)) (#1)
- रैशनल फंक्शन x/(1+|x|) (#2)
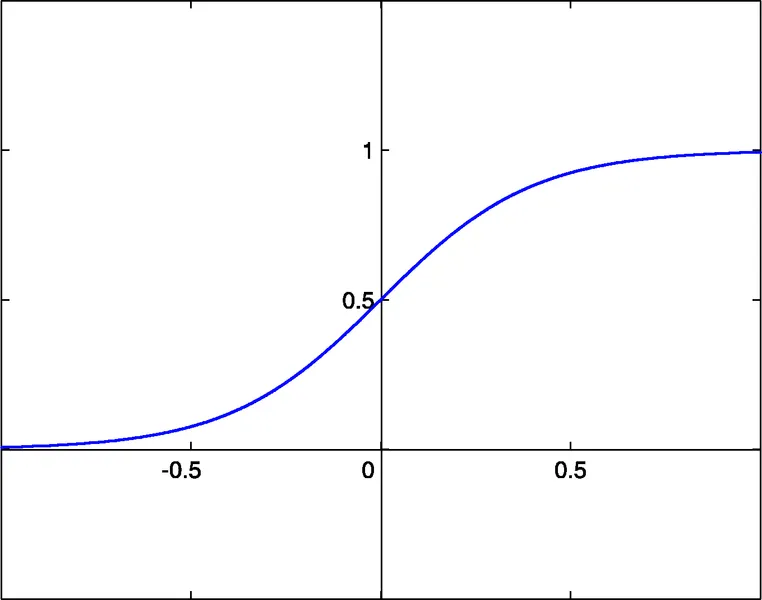
इन फ़ंक्शंस का सक्रियण थ्रेशोल्ड x=0 है। इस थ्रेशोल्ड को प्रत्येक न्यूरॉन के एक अतिरिक्त इनपुट, जिसे बायस इनपुट कहा जाता है, के माध्यम से x अक्ष के साथ स्थानांतरित किया जा सकता है, जिसे एक वेट भी सौंपा गया है।
इनपुट्स, आउटपुट्स, हिडन लेयर्स, इन लेयर्स में न्यूरॉन्स की संख्या और सिनैप्स वेट्स के मान एक FFNN को पूरी तरह से परिभाषित करते हैं, यानी यह नॉन-लिनियर मॉडल जो वह बनाता है। वेट्स ढूंढने के लिए नेटवर्क को प्रशिक्षित किया जाना चाहिए। सुपरवाइज्ड ट्रेनिंग के दौरान, कई सेटों में पिछले इनपुट्स और संबंधित अपेक्षित आउटपुट्स को नेटवर्क में फीड किया जाता है। वेट्स को नेटवर्क आउटपुट्स और अपेक्षित आउटपुट्स के बीच सबसे छोटे त्रुटि को प्राप्त करने के लिए ऑप्टिमाइज़ किया जाता है। वेट ऑप्टिमाइजेशन की सबसे सरल विधि बैक-प्रोपगेशन है, जो एक ग्रेडिएंट डीसेंट विधि है। संलग्न ट्रेनिंग फंक्शन Train() इस विधि के एक संस्करण का उपयोग करता है, जिसे Improved Resilient Back-Propagation Plus (iRProp+) कहा जाता है।
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.17.1332
ग्रेडिएंट-आधारित ऑप्टिमाइजेशन विधियों का मुख्य नुकसान यह है कि वे अक्सर स्थानीय न्यूनतम को पाते हैं। ऐसे अराजक श्रृंखलाओं के लिए जैसे कि कीमतों की श्रृंखला, ट्रेनिंग त्रुटि सतह का एक बहुत जटिल आकार होता है जिसमें बहुत से स्थानीय न्यूनतम होते हैं। ऐसे श्रृंखलाओं के लिए, जेनेटिक एल्गोरिदम एक पसंदीदा प्रशिक्षण विधि है।
संलग्न फ़ाइलें:
- BPNN.dll - लाइब्रेरी फ़ाइल
- BPNN.zip - सभी फ़ाइलों का संग्रह जो BPNN.dll को C++ में संकलित करने के लिए आवश्यक हैं
- BPNN Predictor.mq4 - भविष्य के ओपन प्राइस की भविष्यवाणी करने वाला संकेतक
- BPNN Predictor with Smoothing.mq4 - स्मूथ किए गए ओपन प्राइस की भविष्यवाणी करने वाला संकेतक
फ़ाइल BPNN.cpp में दो कार्य हैं: Train() और Test(). Train() उस नेटवर्क को प्रशिक्षित करने के लिए उपयोग किया जाता है जो पिछले इनपुट और अपेक्षित आउटपुट मान पर आधारित होता है। Test() को प्रशिक्षित वेट्स का उपयोग करके नेटवर्क आउटपुट्स की गणना करने के लिए उपयोग किया जाता है।
यहाँ Train() के इनपुट (हरा) और आउटपुट (नीला) पैरामीटर की सूची है:
double inpTrain[] - इनपुट प्रशिक्षण डेटा (1D ऐरे जो 2D डेटा ले जाता है, पुराना पहले)
double outTarget[] - प्रशिक्षण के लिए आउटपुट लक्ष्य डेटा (2D डेटा के रूप में 1D ऐरे, पुराना पहले)
double outTrain[] - प्रशिक्षण से नेटवर्क आउटपुट्स को रखने के लिए आउटपुट 1D ऐरे
int ntr - प्रशिक्षण सेटों की संख्या
int UEW - आरंभ करने के लिए एक्सट. वेट्स का उपयोग करें (1=extInitWt का उपयोग करें, 0=rnd का उपयोग करें)
double extInitWt[] - 3D ऐरे की बाहरी प्रारंभिक वेट्स को रखने के लिए इनपुट 1D ऐरे
double trainedWt[] - प्रशिक्षित वेट्स का 3D ऐरे रखने के लिए आउटपुट 1D ऐरे
int numLayers - परतों की संख्या जिसमें इनपुट, हिडन और आउटपुट शामिल हैं
int lSz[] - लेयर्स में न्यूरॉन्स की संख्या। lSz[0] नेटवर्क इनपुट्स की संख्या है
int AFT - न्यूरॉन एक्टिवेशन फंक्शन का प्रकार (0:sigm, 1:tanh, 2:x/(1+x))
int OAF - 1 आउटपुट परत के लिए एक्टिवेशन फंक्शन को सक्षम करता है; 0 निष्क्रिय करता है
int nep - अधिकतम प्रशिक्षण युग
double maxMSE - अधिकतम MSE; प्रशिक्षण तब रुकता है जब maxMSE तक पहुँच जाता है।
यहाँ Test() के इनपुट (हरा) और आउटपुट (नीला) पैरामीटर की सूची है:
double inpTest[] - इनपुट परीक्षण डेटा (2D डेटा के रूप में 1D ऐरे, पुराना पहले)
double outTest[] - प्रशिक्षण से नेटवर्क आउटपुट्स को रखने के लिए आउटपुट 1D ऐरे (पुराना पहले)
int ntt - परीक्षण सेटों की संख्या
double extInitWt[] - 3D ऐरे की बाहरी प्रारंभिक वेट्स को रखने के लिए इनपुट 1D ऐरे
int numLayers - परतों की संख्या जिसमें इनपुट, हिडन और आउटपुट शामिल हैं
int lSz[] - लेयर्स में न्यूरॉन्स की संख्या। lSz[0] नेटवर्क इनपुट्स की संख्या है
int AFT - न्यूरॉन एक्टिवेशन फंक्शन का प्रकार (0:sigm, 1:tanh, 2:x/(1+x))
int OAF - 1 आउटपुट परत के लिए एक्टिवेशन फंक्शन को सक्षम करता है; 0 निष्क्रिय करता है
आउटपुट परत में एक्टिवेशन फंक्शन के उपयोग का निर्णय आउटपुट की प्रकृति पर निर्भर करता है। यदि आउटपुट बाइनरी हैं, जो अक्सर वर्गीकरण समस्याओं में होता है, तो आउटपुट परत में एक्टिवेशन फंक्शन का उपयोग किया जाना चाहिए (OAF=1)। कृपया ध्यान दें कि एक्टिवेशन फंक्शन #0 (सिग्मोइड) के पास 0 और 1 संतृप्त स्तर होते हैं जबकि एक्टिवेशन फंक्शन #1 और #2 के पास -1 और 1 स्तर होते हैं। यदि नेटवर्क आउटपुट एक मूल्य भविष्यवाणी है, तो आउटपुट परत में कोई एक्टिवेशन फंक्शन की आवश्यकता नहीं होती (OAF=0)।
NN लाइब्रेरी के उपयोग के उदाहरण:
BPNN Predictor.mq4 - भविष्य के ओपन प्राइस की भविष्यवाणी करता है। नेटवर्क के इनपुट सापेक्ष मूल्य परिवर्तनों हैं:
x[i]=Open[test_bar]/Open[test_bar+delay[i]]-1.0
जहाँ delay[i] फिबोनाच्ची संख्या के रूप में गणना की जाती है (1,2,3,5,8,13,21..)। नेटवर्क का आउटपुट अगली कीमत के अपेक्षित सापेक्ष परिवर्तन की भविष्यवाणी करता है। आउटपुट परत में एक्टिवेशन फंक्शन बंद रहता है (OAF=0)।
संकेतक इनपुट:
- extern int lastBar - पिछले डेटा में अंतिम बार
- extern int futBars - भविष्य की बारों की संख्या की भविष्यवाणी करने के लिए
- extern int numLayers - इनपुट, हिडन और आउटपुट सहित परतों की संख्या (2..6)
- extern int numInputs - इनपुट्स की संख्या
- extern int numNeurons1 - पहले हिडन या आउटपुट परत में न्यूरॉन्स की संख्या
- extern int numNeurons2 - दूसरे हिडन या आउटपुट परत में न्यूरॉन्स की संख्या
- extern int numNeurons3 - तीसरे हिडन या आउटपुट परत में न्यूरॉन्स की संख्या
- extern int numNeurons4 - चौथे हिडन या आउटपुट परत में न्यूरॉन्स की संख्या
- extern int numNeurons5 - पांचवे हिडन या आउटपुट परत में न्यूरॉन्स की संख्या
- extern int ntr - प्रशिक्षण सेटों की संख्या
- extern int nep - अधिकतम युगों की संख्या
- extern int maxMSEpwr - सेट्स maxMSE=10^maxMSEpwr; प्रशिक्षण रुकता है < maxMSE
- extern int AFT - एक्टिवेशन फंक्शन का प्रकार (0:sigm, 1:tanh, 2:x/(1+x))
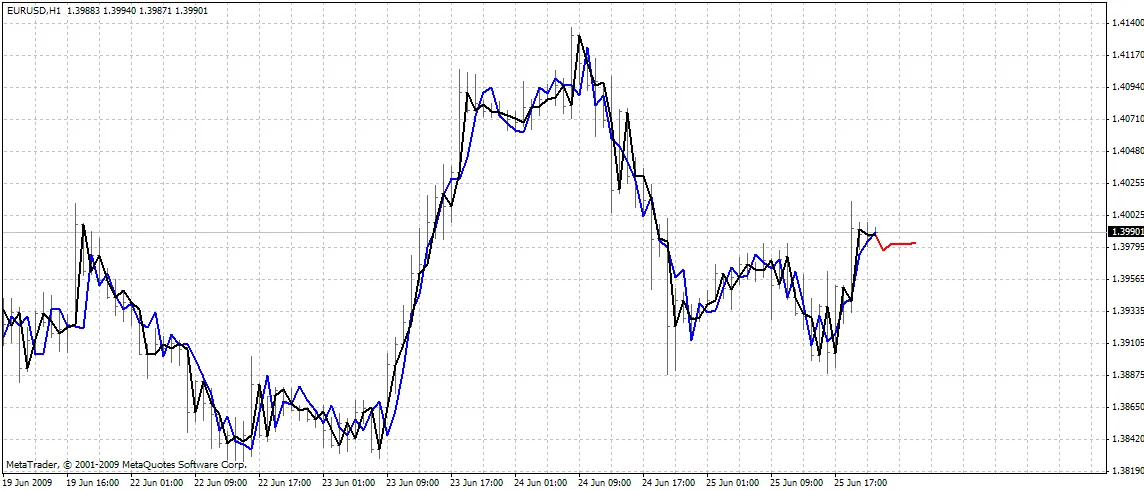
संकेतक चार्ट पर तीन वक्रों को प्लॉट करता है:
- लाल रंग - भविष्य की कीमतों की भविष्यवाणियाँ
- काला रंग - पिछले प्रशिक्षण ओपन प्राइस, जिन्हें नेटवर्क के लिए अपेक्षित आउटपुट के रूप में उपयोग किया गया था
- नीला रंग - प्रशिक्षण इनपुट्स के लिए नेटवर्क आउटपुट्स
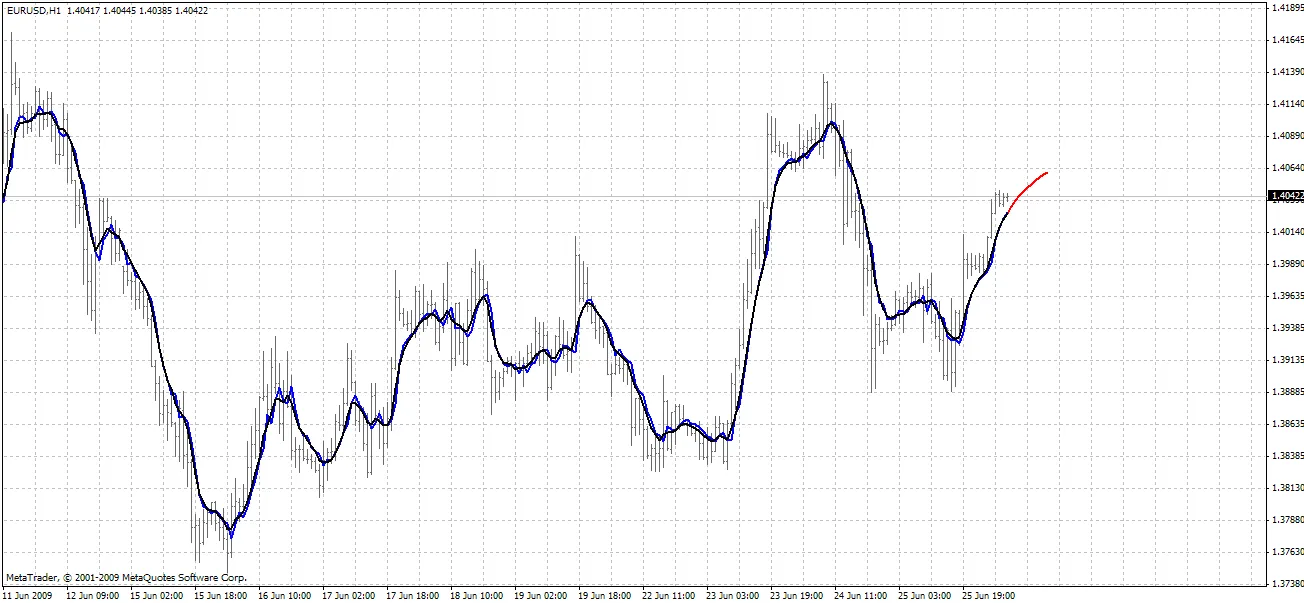
BPNN Predictor.mq4 - भविष्य के स्मूथ किए गए ओपन प्राइस की भविष्यवाणी करता है। यह स्मूथिंग के लिए EMA का उपयोग करता है जिसमें अवधि smoothPer होती है।
सभी सेट अप करना:
- संलग्न BPNN.DLL को C:\Program Files\MetaTrader 4\experts\libraries में कॉपी करें।
- MetaTrader में: उपकरण - विकल्प - विशेषज्ञ सलाहकार - DLL आयात की अनुमति दें।
आप BPNN.zip में स्रोत कोड का उपयोग करके अपना खुद का DLL फ़ाइल भी संकलित कर सकते हैं।
सिफारिशें:
- तीन परतों वाला नेटवर्क (numLayers=3: एक इनपुट, एक हिडन और एक आउटपुट) अधिकांश मामलों के लिए पर्याप्त है। साइबेंको थ्योरम (1989) के अनुसार, एक हिडन लेयर वाला नेटवर्क किसी भी सतत, बहु-परिवर्तनीय फ़ंक्शन का किसी भी इच्छित सटीकता तक अनुमान लगाने में सक्षम है; दो हिडन लेयर्स वाला नेटवर्क किसी भी अविरल, बहु-परिवर्तनीय फ़ंक्शन का अनुमान लगाने में सक्षम है:
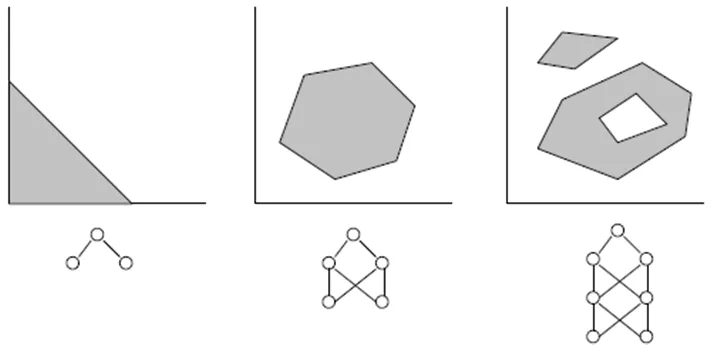
- हिडन लेयर में न्यूरॉन्स की आदर्श संख्या को प्रयास और त्रुटि के माध्यम से खोजा जा सकता है। साहित्य में निम्नलिखित "नियम" मिल सकते हैं: हिडन न्यूरॉन्स की संख्या = (इनपुट्स की संख्या + आउटपुट्स की संख्या)/2, या SQRT(इनपुट्स की संख्या * आउटपुट्स की संख्या)। प्रशिक्षण त्रुटि पर नज़र रखें, जो मीट्रेडर के विशेषज्ञ विंडो में संकेतक द्वारा रिपोर्ट की जाती है।
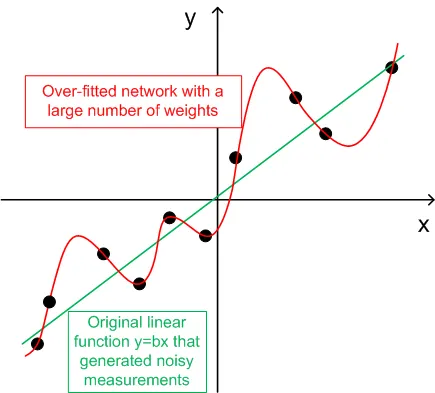
- सामान्यीकरण के लिए, प्रशिक्षण सेटों की संख्या (ntr) को नेटवर्क में कुल वेट्स की संख्या के 2-5 गुना चुना जाना चाहिए। उदाहरण के लिए, डिफ़ॉल्ट रूप से, BPNN Predictor.mq4 12-5-1 नेटवर्क का उपयोग करता है। कुल वेट्स की संख्या (12+1)*5+6=71 है। इसलिए, प्रशिक्षण सेटों की संख्या (ntr) कम से कम 142 होनी चाहिए। सामान्यीकरण और मेमोराइजेशन (ओवर-फिटिंग) का सिद्धांत नीचे दिए गए ग्राफ में समझाया गया है।
- नेटवर्क के लिए इनपुट डेटा को स्थिरता में परिवर्तित किया जाना चाहिए। फ़ॉरेक्स कीमतें स्थिर नहीं होती हैं। इनपुट्स को -1..+1 रेंज में सामान्यित करना भी अनुशंसित किया जाता है।
नीचे दिए गए ग्राफ में एक रेखीय फ़ंक्शन y=b*x (x-इनपुट, y-आउटपुट) दिखाया गया है जिसके आउटपुट को शोर द्वारा भ्रष्टित किया गया है। यह जोड़ा गया शोर फ़ंक्शन के मापे गए आउटपुट (काले बिंदु) को सीधे रेखा से भटकने का कारण बनता है। फ़ंक्शन y=f(x) को एक फीड फॉरवर्ड न्यूरल नेटवर्क द्वारा मॉडल किया जा सकता है। वजन की बड़ी संख्या वाले नेटवर्क को मापी गई डेटा से शून्य त्रुटि के साथ फिट किया जा सकता है। इसका व्यवहार उस लाल वक्र के रूप में दिखाया गया है जो सभी काले बिंदुओं के माध्यम से गुजरता है। हालाँकि, यह लाल वक्र मूल रेखीय फ़ंक्शन y=b*x (हरा) से संबंधित नहीं है। जब इस ओवर-फिटेड नेटवर्क का उपयोग भविष्य के फ़ंक्शन y(x) के मान की भविष्यवाणी करने के लिए किया जाता है, तो यह जोड़े गए शोर के कारण बड़े त्रुटियों का परिणाम देगा।
इन कोडों को साझा करने के लिए लेखक एक छोटा सा अनुरोध करते हैं। यदि आप इन कोडों के आधार पर एक लाभकारी ट्रेडिंग सिस्टम बनाने में सक्षम हैं, तो कृपया मुझे अपने विचार साझा करें, सीधे vlad1004@yahoo.com पर ईमेल भेजकर।
आपको शुभकामनाएँ!




टिप्पणी 0