Autor: gpwr
Histórico de Versões:
26/06/2009 - Adicionado o novo indicador BPNN Predictor com Smoothing.mq4, que suaviza os preços usando EMA antes das previsões.
20/08/2009 - Corrigido o código que calcula a função de ativação do neurônio para evitar exceções aritméticas; atualizado BPNN.cpp e BPNN.dll.
21/08/2009 - Adicionado limpeza de memória ao final da execução da DLL; atualizado BPNN.cpp e BPNN.dll.
Teoria Breve sobre Redes Neurais:
Uma rede neural é um modelo ajustável de saídas como funções de entradas, composta por várias camadas:
- camada de entrada, que consiste nos dados de entrada
- camada oculta, que contém nós de processamento chamados neurônios
- camada de saída, que consiste em um ou mais neurônios, cujas saídas são as saídas da rede.
Todos os nós de camadas adjacentes estão interconectados. Essas conexões são chamadas de sinapses. Cada sinapse tem um coeficiente de escalonamento atribuído, pelo qual os dados propagados através da sinapse são multiplicados. Esses coeficientes de escalonamento são chamados de pesos (w[i][j][k]). Em uma Rede Neural Feed-Forward (FFNN), os dados são propagados das entradas para as saídas. Aqui está um exemplo de FFNN com uma camada de entrada, uma camada de saída e duas camadas ocultas:
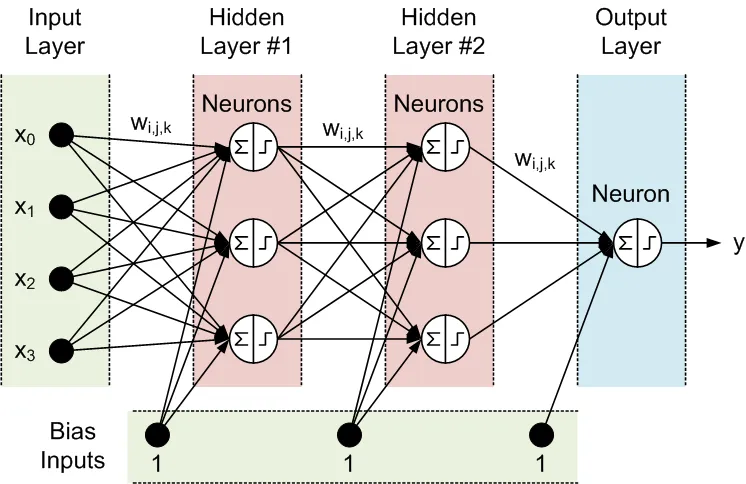
A topologia de uma FFNN é frequentemente abreviada da seguinte forma: <número de entradas> - <número de neurônios na primeira camada oculta> - <número de neurônios na segunda camada oculta> -...- <número de saídas>. A rede acima pode ser referida como uma rede 4-3-3-1.
Os dados são processados pelos neurônios em duas etapas, mostradas dentro do círculo por um sinal de soma e um sinal de passo:
- Todas as entradas são multiplicadas pelos pesos associados e somadas.
- As somas resultantes são processadas pela função de ativação do neurônio, cuja saída é a saída do neurônio.
É a função de ativação do neurônio que confere não linearidade ao modelo de rede neural. Sem ela, não haveria razão para ter camadas ocultas, e a rede neural se tornaria um modelo autorregressivo linear (AR).
As bibliotecas anexadas para funções de NN permitem a seleção entre três funções de ativação:
- sigmóide sigm(x)=1/(1+exp(-x)) (#0)
- tangente hiperbólica tanh(x)=(1-exp(-2x))/(1+exp(-2x)) (#1)
- função racional x/(1+|x|) (#2)
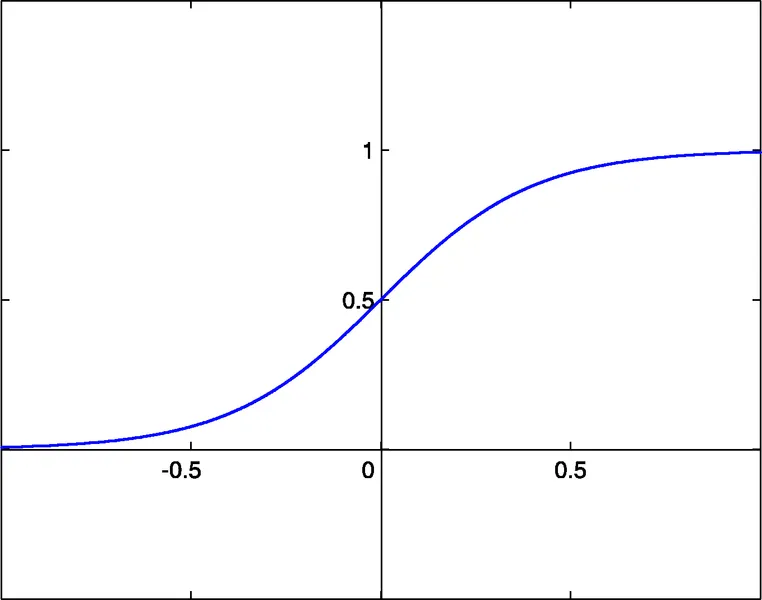
O limite de ativação dessas funções é x=0. Esse limite pode ser movido ao longo do eixo x graças a uma entrada adicional de cada neurônio, chamada de entrada de bias, que também tem um peso atribuído a ela.
O número de entradas, saídas, camadas ocultas, neurônios nessas camadas e os valores dos pesos das sinapses descrevem completamente uma FFNN, ou seja, o modelo não linear que ela cria. Para encontrar os pesos, a rede deve ser treinada. Durante um treinamento supervisionado, vários conjuntos de entradas passadas e as correspondentes saídas esperadas são alimentados à rede. Os pesos são otimizados para alcançar o menor erro entre as saídas da rede e as saídas esperadas. O método mais simples de otimização de pesos é o retropropagação de erros, que é um método de descida de gradiente. A função de treinamento anexada Train() usa uma variante desse método, chamada de Retropropagação Melhorada (iRProp+).
Arquivos anexados:
- BPNN.dll - arquivo de biblioteca
- BPNN.zip - arquivo com todos os arquivos necessários para compilar BPNN.dll em C++
- BPNN Predictor.mq4 - indicador que prevê preços abertos futuros
- BPNN Predictor com Smoothing.mq4 - indicador que prevê preços abertos suavizados
O arquivo BPNN.cpp possui duas funções: Train() e Test(). Train() é usado para treinar a rede com base nos valores de entrada e saída esperados fornecidos. Test() é usado para calcular as saídas da rede usando os pesos otimizados encontrados por Train().
Aqui está a lista de parâmetros de entrada (verde) e saída (azul) de Train():
double inpTrain[] - Dados de treinamento de entrada (array 1D contendo dados 2D, os mais antigos primeiro)
double outTarget[] - Dados de saída alvo para treinamento (dados 2D como array 1D, os mais antigos primeiro)
double outTrain[] - Array 1D de saída para armazenar as saídas da rede do treinamento
int ntr - Número de conjuntos de treinamento
int UEW - Usar Pesos Externos para inicialização (1=usar extInitWt, 0=usar rnd)
double extInitWt[] - Array 1D de entrada para armazenar array 3D de pesos iniciais externos
double trainedWt[] - Array 1D de saída para armazenar array 3D de pesos treinados
int numLayers - Número de camadas incluindo entrada, ocultas e saída
int lSz[] - Número de neurônios nas camadas. lSz[0] é o número de entradas da rede
int AFT - Tipo de função de ativação do neurônio (0:sigm, 1:tanh, 2:x/(1+x))
int OAF - 1 habilita a função de ativação para a camada de saída; 0 desabilita
int nep - Número máximo de épocas de treinamento
double maxMSE - MSE máximo; o treinamento para quando maxMSE é atingido.
Aqui está a lista de parâmetros de entrada (verde) e saída (azul) de Test():
double inpTest[] - Dados de teste de entrada (dados 2D como array 1D, os mais antigos primeiro)
double outTest[] - Array 1D de saída para armazenar as saídas da rede do treinamento (os mais antigos primeiro)
int ntt - Número de conjuntos de teste
double extInitWt[] - Array 1D de entrada para armazenar array 3D de pesos iniciais externos
int numLayers - Número de camadas incluindo entrada, ocultas e saída
int lSz[] - Número de neurônios nas camadas. lSz[0] é o número de entradas da rede
int AFT - Tipo de função de ativação do neurônio (0:sigm, 1:tanh, 2:x/(1+x))
int OAF - 1 habilita a função de ativação para a camada de saída; 0 desabilita.
O uso da função de ativação na camada de saída (valor do parâmetro OAF) depende da natureza das saídas. Se as saídas forem binárias, o que é comum em problemas de classificação, a função de ativação deve ser usada na camada de saída (OAF=1). É importante notar que a função de ativação #0 (sigmóide) possui níveis saturados em 0 e 1, enquanto as funções de ativação #1 e #2 têm níveis em -1 e 1. Se a saída da rede for uma previsão de preço, então não é necessário usar a função de ativação na camada de saída (OAF=0).
Exemplos de uso da biblioteca NN:
BPNN Predictor.mq4 - prevê preços abertos futuros. As entradas da rede são alterações de preços relativas:
x[i]=Open[test_bar]/Open[test_bar+delay[i]]-1.0
onde delay[i] é calculado como um número de Fibonacci (1,2,3,5,8,13,21..). A saída da rede é a mudança relativa prevista do próximo preço. A função de ativação é desligada na camada de saída (OAF=0).
Entradas do indicador:
extern int lastBar - Última barra nos dados passados
extern int futBars - Número de barras futuras a prever
extern int numLayers - Número de camadas incluindo entrada, ocultas e saída (2..6)
extern int numInputs - Número de entradas
extern int numNeurons1 - Número de neurônios na primeira camada oculta ou de saída
extern int numNeurons2 - Número de neurônios na segunda camada oculta ou de saída
extern int numNeurons3 - Número de neurônios na terceira camada oculta ou de saída
extern int numNeurons4 - Número de neurônios na quarta camada oculta ou de saída
extern int numNeurons5 - Número de neurônios na quinta camada oculta ou de saída
extern int ntr - Número de conjuntos de treinamento
extern int nep - Número máximo de épocas
extern int maxMSEpwr - define maxMSE=10^maxMSEpwr; o treinamento para quando maxMSE é atingido
extern int AFT - Tipo de função de ativação (0:sigm, 1:tanh, 2:x/(1+x))
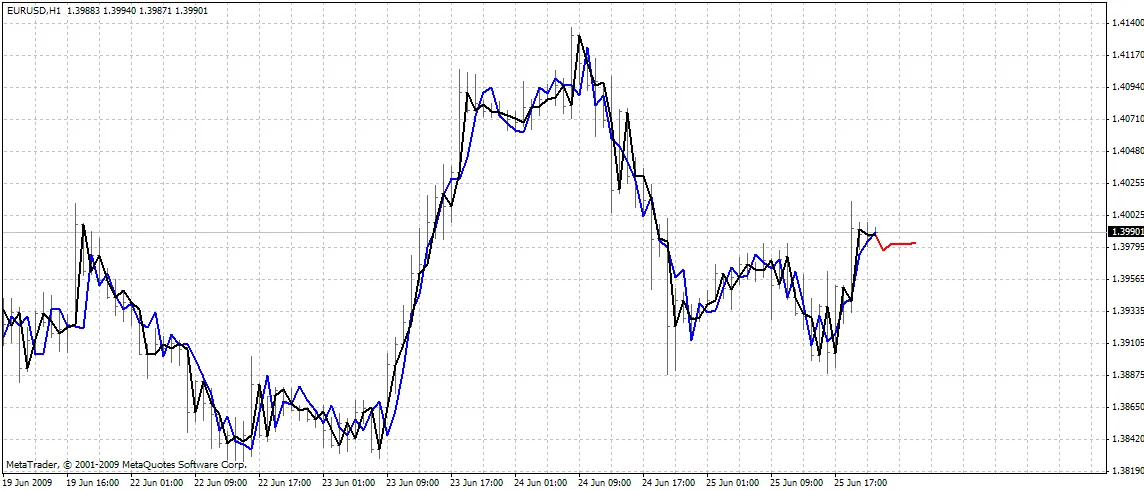
O indicador plota três curvas no gráfico:
- cor vermelha - previsões de preços futuros
- cor preta - preços abertos de treinamento passados, que foram usados como saídas esperadas para a rede
- cor azul - saídas da rede para as entradas de treinamento
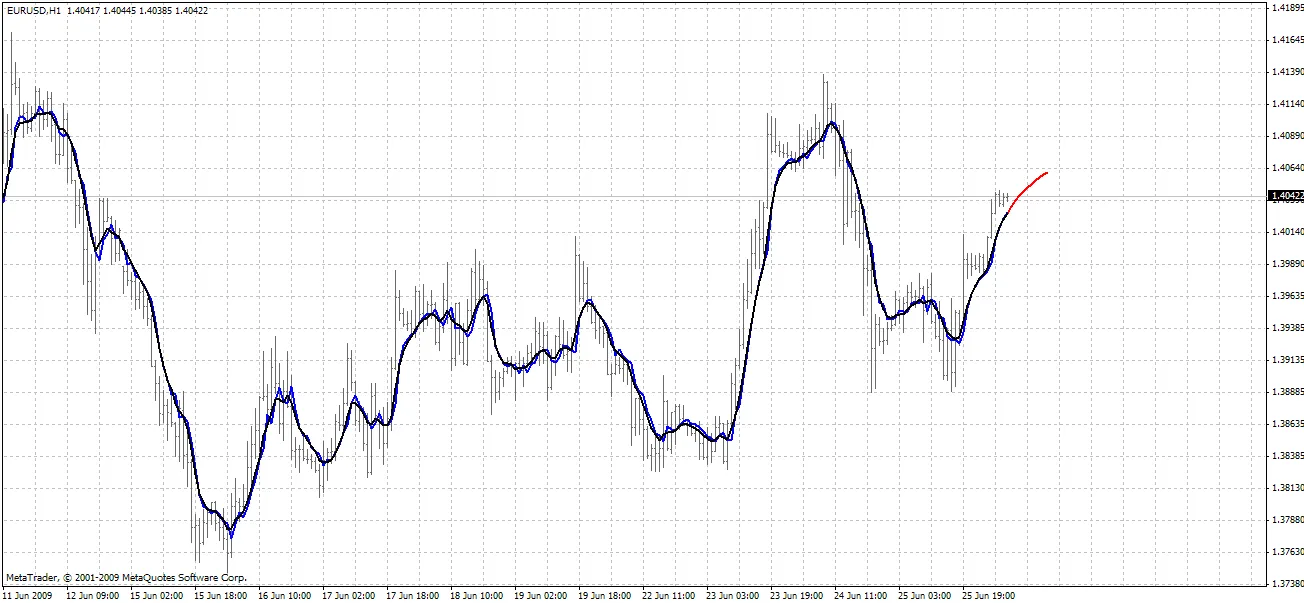
BPNN Predictor.mq4 - prevê preços abertos suavizados futuros. Utiliza suavização EMA com período smoothPer.
Configurando tudo:
- Copie o BPNN.DLL anexado para C:\Program Files\MetaTrader 4\experts\libraries.
- No MetaTrader: Ferramentas - Opções - Expert Advisors - Permitir importação de DLLs.
Você também pode compilar seu próprio arquivo DLL usando os códigos fonte em BPNN.zip.
Recomendações:
- Uma rede com três camadas (numLayers=3: uma de entrada, uma oculta e uma de saída) é suficiente para a grande maioria dos casos. Segundo o Teorema de Cybenko (1989), uma rede com uma camada oculta é capaz de aproximar qualquer função contínua multivariada com o grau de precisão desejado; uma rede com duas camadas ocultas é capaz de aproximar qualquer função multivariada descontínua.
- O número ideal de neurônios na camada oculta pode ser encontrado através de tentativa e erro. As seguintes "regras práticas" podem ser encontradas na literatura: número de neurônios ocultos = (número de entradas + número de saídas)/2, ou SQRT(número de entradas * número de saídas). Acompanhe o erro de treinamento, que é relatado pelo indicador na janela de especialistas do MetaTrader.
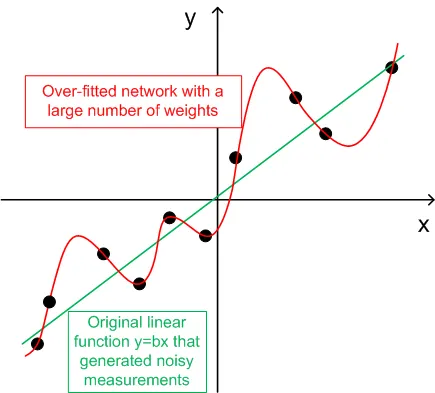
- Para generalização, o número de conjuntos de treinamento (ntr) deve ser escolhido entre 2 a 5 vezes o número total de pesos na rede. Por exemplo, por padrão, BPNN Predictor.mq4 utiliza uma rede 12-5-1. O número total de pesos é (12+1)*5+6=71. Portanto, o número de conjuntos de treinamento (ntr) deve ser de pelo menos 142. O conceito de generalização e memorização (over-fitting) é explicado no gráfico abaixo.
- Os dados de entrada para a rede devem ser transformados para estacionários. Os preços Forex não são estacionários. Também é recomendado normalizar as entradas para o intervalo -1..+1.
O gráfico abaixo mostra uma função linear y=b*x (x-entrada, y-saída) cujas saídas estão corrompidas por ruído. Esse ruído adicionado faz com que as saídas medidas da função (pontos pretos) se desviem de uma linha reta. A função y=f(x) pode ser modelada por uma rede neural feed-forward. A rede com um grande número de pesos pode ser ajustada aos dados medidos com erro zero. Seu comportamento é mostrado como a curva vermelha passando por todos os pontos pretos. No entanto, essa curva vermelha não tem relação com a função linear original y=b*x (verde). Quando essa rede sobreajustada é usada para prever valores futuros da função y(x), resultará em grandes erros devido à aleatoriedade do ruído adicionado.
Em troca de compartilhar estes códigos, o autor tem um pequeno favor a pedir. Se você conseguir criar um sistema de negociação lucrativo com base nesses códigos, por favor, compartilhe sua ideia comigo enviando um e-mail diretamente para vlad1004@yahoo.com.
Boa sorte!




Comentário 0